DoS attacks on blogs – part 2
One of the things I did after the server was restarted, was to define s throttle on the blogs, the wiki and the download area. This wioll oprevent this number of concurrent accesses to them, limiting the risks. It may mean that when I get a lot of requests, some will have to wait a bit longer, or will be queued for some time, or get a “Server busy” error. The issue is clearly visisble in yesterday’s history. Not so much in CPU – there are some spikes up to 25%:

At times there have been peaks in CPU, normally it’s just a few\percent, these spikes up to 25 are remarkable, esepcially in the timeframe in which they occur…
In memory usage – especially pagefile usage – the problem is clear:
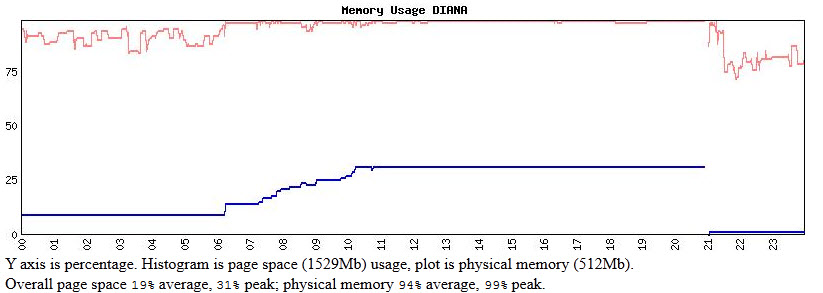
Free memory is exhausted, but there is space enough avaliable in the pagefile, and far more cqan be paged into the files; but since none of the processes clearly ran out of virtual memory, there is something else that blocked processing. The only culprit in that case, might be MySQL….
The number of processes:

runs in to the roof – in steps, and it follows memory usage: starting to rise at six to stablize just a few minutes later, until the numbert of processes increases again at 7, again stabilizes at 9, and again increasing in steps until the system of out of slots at 10; in the next half hour, is seems some processes com to an end but immediately, that free slot is taken again….From that moment on, until the system is rebootes at 21:00, no new processes can be created; once in a while one ends, but another will take the slot immedeately…
Paging show2s a massive peak at 6:00 and 7:00.
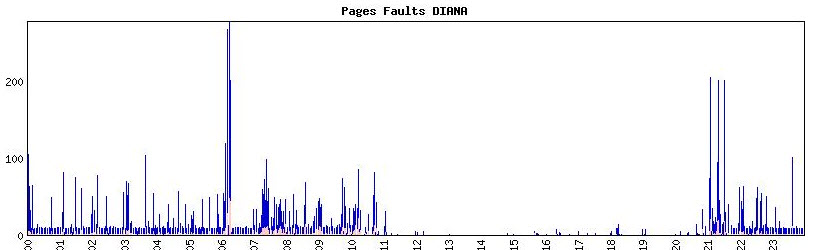
These will be the moments that the large amount of processes are created. It matches the graph seen yesterday on the amount of requests on these moments.
The graph of buffered IO shows the same peaks:
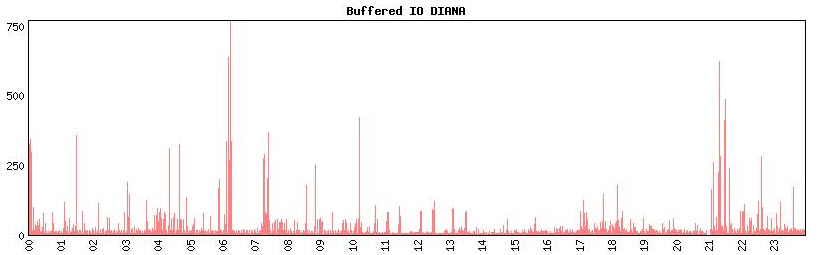
So the problem started at 6:00, stabalized until 7:00, and then contibued until the system ran out of resources at about 10:30 (local time, which is UTC without DST on the system).
Armed with these data, I searched the access log.
At 4:00, 66.249.66.186 requested a few pages in the SYSMGR blog, but there were a few minutes between them and that is hardly noticble. Nothing weird, actually, this happens more often.
But at 6:00, 204.11.219.95 kicks in. Within 16 minutes this address fires 50 subsequent GETs on the Tracks blog index; the fist 20 succee; he get’s 503 errors on the next 5; the next 5 succeed, the next 6 result in 502 errors followed by succeeding.
About 15 minutes later, at 6:39, addresses 66.249.66.186 and 66.249.71.152 start accessing the SYSMGR blog index with straight requests. Several other addesses do the same for RSS feeds, others scanning for monthly indices to be displayed. Not that often – verey few minutes, but continuously. Most, of course, ending in a 500-style error after 10:30….
These 66.xxx.xxx.xxx addresses are owned by Google, and so do some of the RSS feeds. This is no big deal, it’s rather nomal. These come with a larger interval. The real culprit seems to be 204.11.219.95:
$ dig -x 204.11.219.95
; < <>> DiG 9.3.1 < <>> -x 204.11.219.95
;; global options: printcmd
;; Got answer:
;; ->>HEADER< <- opcode: QUERY, status: NXDOMAIN, id: 6130
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 0
;; QUESTION SECTION:
;95.219.11.204.in-addr.arpa. IN PTR
;; ANSWER SECTION:
95.219.11.204.in-addr.arpa. 43200 IN CNAME 95.219.11.204.in-addr.networkvirtue.com.
;; AUTHORITY SECTION:
networkvirtue.com. 2560 IN SOA a.ns.networkvirtue.com. hostmaster.networkvirtue.com. 1305226632 16384 2048 1048576
2560
;; Query time: 5843 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Fri Jan 13 13:10:14 2012
;; MSG SIZE rcvd: 149
$
$ whois 204.11.219.95
----Server: whois.arin.net [AMERICAS] response for 204.11.219.95
#
# Query terms are ambiguous. The query is assumed to be:
# "n 204.11.219.95"
#
# Use "?" to get help.
#
#
# The following results may also be obtained via:
# http://whois.arin.net/rest/nets;q=204.11.219.95?showDetails=true&showARIN=false&ext=netref2
#
Peak Web Hosting Inc. PEAK-WEB-HOSTING (NET-204-11-216-0-1) 204.11.216.0 - 204.11.223.255
Gal Halevy GAL-HALEVY-NETWORK (NET-204-11-219-64-1) 204.11.219.64 - 204.11.219.127
#
# ARIN WHOIS data and services are subject to the Terms of Use
# available at: https://www.arin.net/whois_tou.html
#
So I know where to signal abuse.
By the way: Mail reception stalled as well:
%%%%%%%%%%% OPCOM 12-JAN-2012 10:14:27.38 %%%%%%%%%%%
Message from user INTERnet on DIANA
INTERnet ACP SMTP Abort Request from Host: 192.168.0.2 Port: 54120
%%%%%%%%%%% OPCOM 12-JAN-2012 10:14:27.38 %%%%%%%%%%%
Message from user INTERnet on DIANA
INTERnet ACP AUXS failure Status = %SYSTEM-F-NOSLOT
Same problem….
