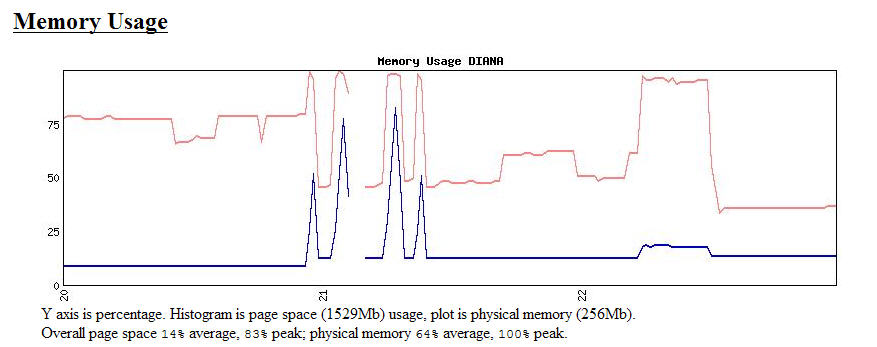
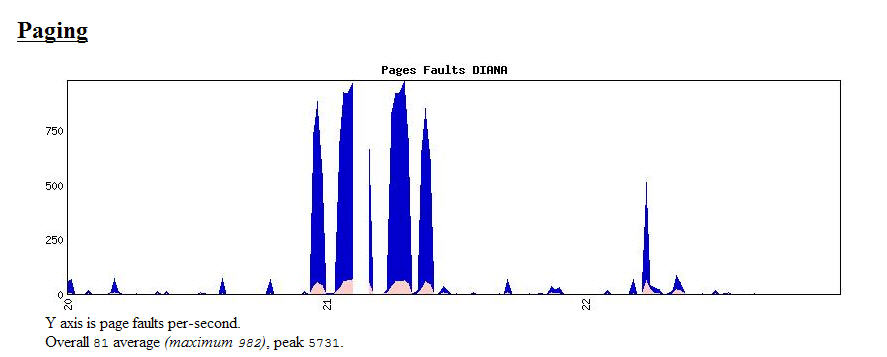
Severe problems
Normally, it’s a god thing to combine fully unrelated issues if possible. In this case, updates to Diana require a reboot, and some work needed to be done on the electrical system, and that meant power down.
So I installed the patches, and shutdown Diana – and the disk controller. Next, take power down, do the work to be done and power the whole bunch up.
That however, proved a bit more cumbersome than I thought: firing up both the Alpha AND the disk controller AND the fully loaded diskshelves gave a spike on the pwoer grid that caused the security switch to fall and so power did not return. I switched all computer hardware off power, and installed power afterwards – unit by unit.
The problems werre revealed soon. VERY soon..
It looked as af the disks shelves and the HSX50 controller came up nice – except for one disk, that failed to spin up.
Took that one off the shelve, and restarted the controller.
Next, start Diana. Same problem as a few weeks ago: come up, and suddenly stop responding. Switching the system off and on several times, restarting the HSZ controller – finally it worked, all of a sudden. So I kept it running.
Booting revealed a failure starting MySQL – and the webs didn’t work either. It turned out that the disk containing the webs could not be mounted due to parity errors in accessing SECURITY.SYS. That means that the disk had to be re-initialized, and I would have to restore everything from backup. I did make a full backup of the whole disk some time ago, but the public web is copied each Monday, and nothing has changed in these static pages last week. Just the operator logs (and their zips) would – once again – be lost.
So I did an INIT of the webdisk, and restored the backup. That took all evening yesterday and part of the night.
In thge mean time, I took the opportunity to do some ‘de’-tuning of MySQL so it requires about half the memory it did take. It will slow down all blogs, but stability is more important – so if it doesn’t require so many pages, it might less easily run into “not enough core”.
This morning the webdisk could be mounted, the diskcontaines could be connected to the LD driver, but mount simply failed. Completely. The error count on the disk went up, so cahnces are the disk is really broken.
To speed things up, I installed the backup disk, and again, Mount of the disk containers wasn’t fully free of errors, but they could be mounted. That meant I had the webs back (though somewhat outdated), and I could restore the datases.
That’s what I thought.
I knew I had to prepare something: create an empty database, and execute the full backup SQL file. It took soemwhat more work: I had te refer back to the original installation page, and redo some work. I found the databases were still found but accessing tables failed. No wonder: the data dictionary was still intact and MySQL refers to these .FRM files! Renamed them, and created new databases using PHPMyAdmin. Now, the databases were back in order. This has been executed on a new containr, only 4Gb in size – big enough to hold the databases.
As a follow-up, I cleared the old database diskcontainer and copied all webs to that, and after that, restored the backup PUBLIC web onto that, and relabeled the volume – this is curently in progress.
After dismounting and disconnecting the smaller container, I will rename the container files, name the former database container to be the web container, connect it to LD and mount the volume. Hopefully, It will be up-to-date after that.
Backing up this whole disk will take the rest of the night.
Now what caused all this? It’s mainly hardware failure – it can very well have to do with the power returning to the systems. I’ll need to investigate Diana for this, but that means: no alternative – yet. The only ones I have as an alternative at the moment is the Alphaserver 400 or one of the AlphaSattion 200’s. Both lack memory, and are much slower – not just clockticks, but processor as well (EV4, compared with EV56 in Diana).
The Alpha1000 and 2000 don’t start at the moment, and require to be set up to use the shared SCSI as well. I do have cards left ….
One more MySQL failure
MySQL once again ran into an ACCVIO error….